알고리즘 문제를 풀면서 연결 리스트를 다방면으로 활용하지 못하는 것 같아서 강의를 보면서 개념 정리를 다시 꼼꼼하게 해 보았다.
아래 링크에 있는 강의를 통해 공부하였다.
리스트
- 하나 이상의 데이터가 있으며, 순서가 의미를 가지는 것
- 기본적인 연산 종류 : 삽입, 삭제, 검색 등
- 대표적인 구현 방법 : 배열, 연결 리스트
배열
- 크기가 고정되어있어서 중간에 원소를 삽입하거나 삭제할 경우 다수의 데이터가 이동함으로써 소모가 크다.
- 대대적인 재배치가 필요하다.
⭐연결 리스트
- 중간 삽입과 삭제를 쉽게 할 수 있다.
- 길이에 제한이 없다.
- 랜덤 액세스가 불가능하다. (아래에서 자세히 설명)

위 그림을 통해 차이점을 좀 더 명확히 알 수 있다.
배열은 정해진 크기 내에서 순서가 정해진 채로 "104자리는 September"가 고정이 되어있다.
그래서 array [3]이라고 하면 바로 September라는 값을 구할 수 있다.
하지만, 연결 리스트는 정해지지 않은 저장공간에 데이터를 저장해둔다.
각 데이터에 다음 노드에 대한 정보만 저장이 되어 있기 때문에 array [3]을 찾으려면
array [0] -> array [1] -> array [2] -> array [3] 이렇게 타고 들어가야 하기 때문에
이러한 부분을 랜덤 액세스가 불가능하다고 하는 것이다.
연결 리스트를 좀 더 보기 쉽게 그리면 이렇게 된다.

이제 연결리스트를 직접 구현해볼 건데 그전에 연결 리스트의 구조를 자세히 살펴보자.
연결 리스트의 구조
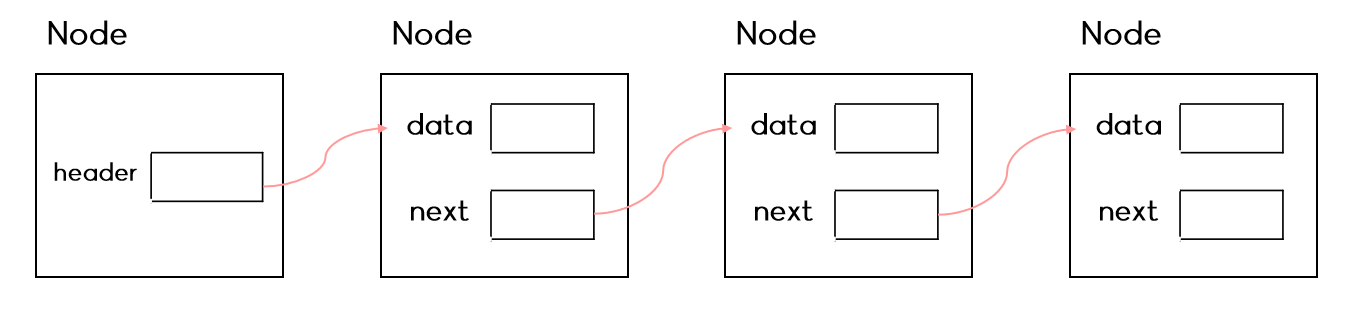
Node(노드)는 연결 리스트를 구성하는 기본 단위이다.
Node는 Java에서는 보통 Class로 선언하여 연결 리스트를 만든다.
보통은 하나의 데이터 객체 + 다음 노드의 주소 이렇게 구성이 되어 있다.
하지만 하나의 데이터 객체가 아닌 노드가 여러 개의 데이터를 가져야 하는 경우가 있다.
그럴 경우 Java에서는 여러 개의 데이터가 들어 있는 하나의 클래스를 노드의 데이터 객체 하나로 만들어서 구현하는 게 좀 더 일반적이다.
노드 자체에 여러 개의 데이터가 들어가도 상관은 없다!
연결 리스트 다양한 메서드 구현해보기
Node
public class Node<T> {
public T data;
public Node<T> next; //다음 노드의 주소 (나와 똑같은 노드를 가리킨다)
//나 자신하고 동일한 타입이어야 함
public Node( T item ){
data = item;
next = null;
}
}
LinkedList
public class MySingleLinkedList<T> {
public Node<T> head; //연결리스트의 첫 번째 노드의 주소를 가리키고 있다.
public int size; //지금 현재 노드의 개수
//초기화 작업
public MySingleLinkedList(){
head = null
size = 0;
}
}
addFirst
1. 새로운 노드를 만들고 추가할 데이터를 새 노드에 저장한다.
2. 새로운 노드의 next 필드가 현재의 head 노드를 가리키도록 한다.
3. 새로운 노드를 새로운 head 노드로 한다.
public void addFirst( T item ) {
Node<T> newNode = new Node<T>(item); //1번
newNode.next = head;
head = newNode;
size++; //연결리스트의 사이즈를 항상 체크
} Tip!
T : type parameter
type parameter를 포함하는 객체를 new 명령어로 생성할 때
T t = new T(); -> type paramter는 가상 클래스여서 이렇게 적으면 틀린 코드!
T [] array = new T [100] -> 이것도 안 됨
T타입을 가지는 다른 클래스의 객체를 생성하는 것은 괜찮음!
Node <T> newNode = new Node <T>(item); -> 이런 것은 괜찮음
T를 type paramter로 가지는 배열 생성은 안 됨
Node<T> [] arr = new Node <T>[100]; => 이게 제일 헷갈리는 부분!! 잘 알아두기!
연결 리스트를 다루는 프로그램에서 가장 주의할 점은 내가 작성한 코드가
일반적인 경우만이 아니라 특수한 혹은 극단적인 경우에도 문제없이 작동하는지
철저히 확인하는 것이다. 이 경우에는 기존의 연결 리스트의 크기가 0인 경우,
즉, head가 null인 경우에도 문제가 없는지 확인해야 한다. 문제가 없는가?
(예시) addFirst메서드가 노드가 하나도 없는 경우에 잘 성립되는가??
addAfter
1. 새로운 노드를 만들고 데이터를 저장한다.
2. 새로운 노드의 next 필드가 before의 다음 노드를 가리키도록 한다.
3. 새로운 노드를 before의 다음 노드로 만든다.
public void addAfter( Node<T> before, T item ){
Node<T> temp = new Node<T>(item);
temp.next = before.next; //장소 = 값
before.next = temp;
size++;
}before 다음의 노드가 없어도 성립이 잘 되는가? 예외는 없는가? 를 고민해보자!
addBefore
- p앞에 새로운 노드를 만드는 것은 p뒤에 새로운 노드를 만드는 것보다 훨씬 복잡하다.
- p앞의 노드의 next값에 새로운 노드를 넣어야 하는데, p앞의 노드 주소를 아는 방법이 간단하지 않다. (모든 노드들이 이전 노드의 값은 가지지 않고 다음 노드의 값만 가지고 있기 때문에)
removeFirst
1. head가 null이 아니라면 head가 현재 head 노드의 다음 노드를 가리키게 만든다.
public T removeFirst(){
if(head == null) return null; //노드가 하나도 없는 경우
T temp = head.data;
head = head.next;
size--;
return temp;
}두 번째 노드가 반드시 존재한다는 전제가 없음. 배열이 노드 하나밖에 없는 경우에 성립이 되는가?
removeAfter
1. before의 다음 노드가 null이 아니라면 before의 next 필드가 현재 next노드의 다음 노드를 가리키게 만든다.
public T removeAfter( Node<T> before ){
if(before.next == null) return null;
T temp = before.next;
before.next = before.next.next;
size--;
return temp;
}- 단순연결리스트에 어떤 노드를 삭제할 때는 삭제할 노드의 바로 앞 노드의 주소가 필요하다. 삭제할 노드의 주소만으로는 삭제할 수 없다.
indexOf (검색)
- 연결리스트의 노드들을 처음부터 순서대로 방문하는 것을 순회(traverse)한다고 말한다. indexOf 메서드는 입력된 데이터 item과 동일한 데이터를 저장한 노드를 찾아서 그 노드 번호(index)를 반환한다. 그것을 위해서 연결 리스트를 순회한다.
public int indexOf( T item ) {
Node<T> p = head;
int index = 0;
while (p != null) {
if(p.data.equals(item)) return index;
p = p.next;
index++;
}
return -1;
}
getNode
- index번째 노드의 주소를 반환한다.
public Node<T> getNode( int index ){
if(index < 0 || index >= size) return null;
Node<T> p = head;
for(int i=0; i<index; i++){
p = p.next;
}
return p;
}
get
- index번째 노드에 저장된 데이터를 반환한다.
public T get( int index ) {
//위의 getNode와 같은 코드를 작성해야하는 것을
//좀 더 효율적으로 작성하기 위해 메소드 사용
if(index < 0 || index >= size) return null;
return getNode(index).data;
}
add
- index번째 위치에 새로운 데이터를 삽입한다.
public void add ( int index, T item ) {
//인덱스의 유효성 검사
//새로운 애들을 추가하는 거라서 최종 길이는 size+1이 되기 때문에 범위 변경
if( index < 0 || index > size ) return;
//index가 0일 때는 이전 노드가 없기 때문에 예외로 처리해주기
if(index == 0) addFirst( item );
else {
Node<T> q = getNode( index-1 );
addAfter( q, item );
}
}
T remove (int index)
- index번째 노드를 삭제하고, 그 노드에 저장된 데이터를 반환한다.
public T remove ( int index ) {
if( index < 0 || index >= size ) return null;
if( index == 0 ) return removeFirst();
Node<T> prev = getNode( index-1 );
return removeAfter( prev );
}
T remove (T item)
- 입력된 데이터를 저장한 노드를 찾아 삭제한다. 삭제된 노드에 저장된 데이터를 반환한다.
public T remove ( T item ) {
//노드를 삭제할 때 이전노드의 정보를 알아야하는데
//p가 삭제할 노드고, q를 그 이전노드로 동시에 옮겨가면서
//p가 찾아졌을 때, q정보를 가지고 p를 삭제시킨다.
Node<T> p = head, q = null;
while( p != null && !p.data.equals( item )){
q = p;
p = p.next;
}
if( p == null ) return null;
//item이 제일 첫 번째 노드일 때 (q가 null로 처리되기 때문에 미리 예외 처리)
if( q == null ) return removeFirst();
else return removeAfter(q);
}
강의를 토대로 개인적으로 정리한 내용입니다.
혹시나 틀린 내용이 있으면 댓으로 알려주세요~!
'Java' 카테고리의 다른 글
| [JAVA ː 자바] 구구단 가로/세로 출력하기 (0) | 2020.04.13 |
|---|